あなたは、エクスポートのオプションを持たないウェブサイトから情報を簡単に取得する必要がある状況に出くわしたことはありませんか?
この状況は、私のクライアントに起こりました。そのクライアントは、プラットフォームから、何としてでも電子メールアドレスのリストを取得したいと思っていました。しかし、そのプラットフォームはクライアントの持つデータのエクスポートを許可しておらず、UI(ユーザーインターフェース)上にある一連のハードルによってデータを隠していたのです。クライアントは、各電子メールを手作業でコピーしてくれるデータ入力の業者を雇うのに法外な代金を支払うところでした。幸運にも彼女は、ウェブスクレイピングが、この状況を打開してくれる未来につながる道であることを思い出しました。ウェブスクレイピングは、「ビッグ・ブラザー(ジョージ・オーウェルの小説『1984年』に登場する架空の人物)」に対抗するための、私の大好きな方法でもあります。私は、(たった15分で)その状況を切り開き、彼女が法外な代金を払うのを防ぎました。きっと他にも同様の問題に直面している人がいることでしょう。そのため、ウェブブラウザを使用してデータを取得する(取り戻す)プログラムを書く方法を皆さんと共有したいと思います!
簡単な例を使って、一緒に練習しましょう。Google検索のスクレイピングです。あまりクリエイティブではなくてごめんなさい。でも、初心者には最適の方法だと思います。
必要なもの
Python(私が使用しているバージョンは2.7です)
- Splinter(Seleniumに基づく)
- Pandas
Chrome
Chromedriver
もしあなたがPandasを使用しておらず、面倒くさがりな性格ならば、絶対に必要かつ非常に有用なライブラリを含むPythonを配布しているAnacondaのサイトに行くことをお勧めします。
それ以外の場合は、pipを使ってターミナル/コマンドラインとすべての依存関係からPandasをダウンロードしてください。
pip install pandas
Splinterを使用していない場合(またAnacondaのPythonを使用していない場合)は、単純にpipを使ってターミナル/コマンドラインからPandasをダウンロードしてください。
pip install splinter
Splinterを使用していない場合(またAnacondaのPythonを使用している場合)は、Anacondaのパッケージマネージャーを使ってターミナル/コマンドラインからPandasをダウンロードしてください。
conda install splinter
これを(利点の多い)仮想環境で設定したいものの、何から始めるべきかわからない場合は、仮想環境に関する私たちの他のブログ記事を読んでみてください。
ステップ1:ライブラリおよびブラウザ
ここでは、必要なすべてのライブラリをインポートし、ブラウザオブジェクトを設定します。
from splinter import Browser
import pandas as pd
# open a browser
browser = Browser('chrome')
スクレイピングしようとしているページがレスポンシブデザインの場合は、set_window_sizeを使用して必要な要素がすべて表示されるようにしてください。
# Width, Height
browser.driver.set_window_size(640, 480)
上記のコードで、Google Chromeのブラウザを開くことができます。これでブラウザの設定が完了しました。Googleにアクセスしてみましょう。
browser.visit('https://www.google.com')
ステップ2:ウェブサイトの探求
これでフロントページにアクセスできましたね。次に、ウェブサイトをナビゲートする方法に焦点を当てましょう。これを行うためには、主に以下の2つのステップがあります。
- 何か(HTML要素)を見つける
- アクションを実行する
HTML要素を見つけるには、Chromeデベロッパーツール(検証機能)を使用する必要があります。ウェブサイトを右クリックして、「検証」を選択してください。Chromeブラウザの右側でボックスが開きます。次に、(赤でハイライトされている)検証アイコンをクリックしてください。
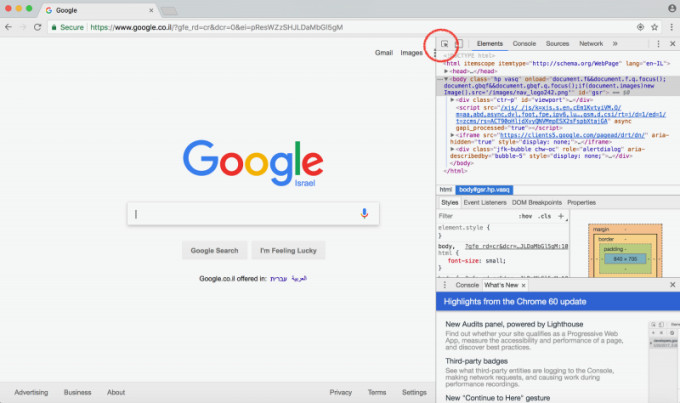
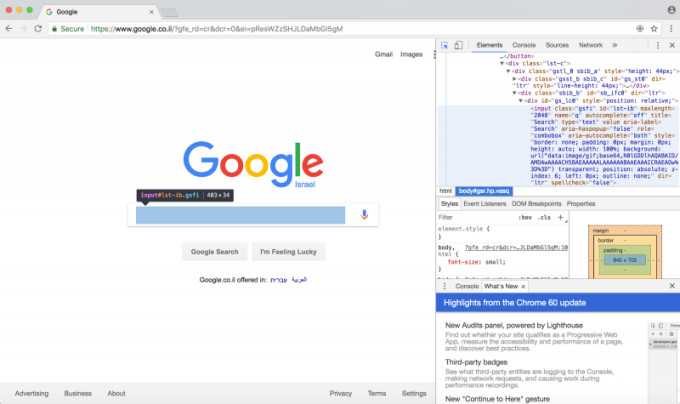
次に、検証カーソルを使用して、制御したいウェブサイトのセクションをクリックしてください。クリックすると、そのセクションを構成するHTMLが右側にハイライト表示されます。下の写真では、「input」である検索バーをクリックしています。
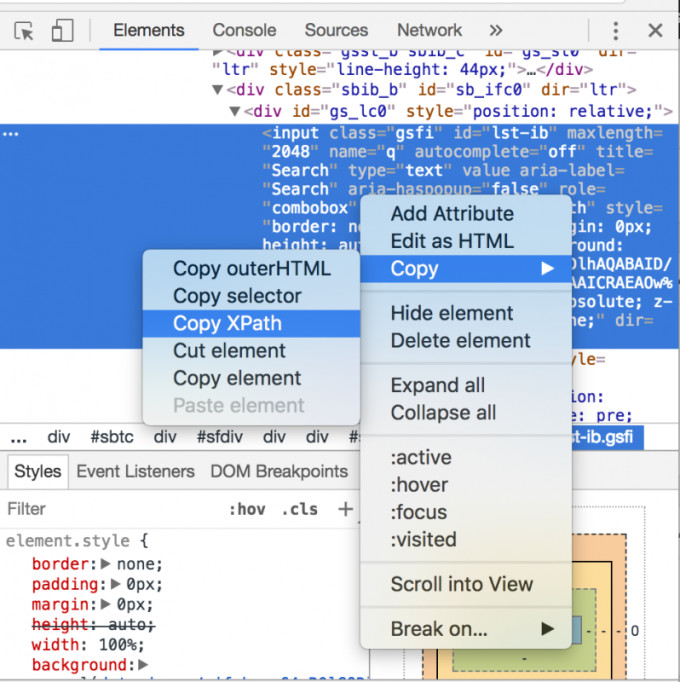
次に、HTML要素を右クリックし、「Copy」→「Copy XPath」の順に選択してください。
おめでとうございます!これで王国への鍵を手に入れましたね。次は、Splinterを使ってPythonからHTML要素を制御する方法に移りましょう。
ステップ3:ウェブサイトの制御
XPathは最も重要な情報です!まず、Pythonの変数に代入することでこのXPathを保護しましょう。
# I recommend using single quotes
search_bar_xpath = '//*[@id="lst-ib"]'
次に、このXPathをSplinter Browserオブジェクトの素晴らしいメソッドであるfind_by_xpath()に渡します。このメソッドは、渡したXPathに一致するすべての要素を抽出し、Elementオブジェクトのリストを返します。要素が1つしかない場合は、長さ1のリストを返します。他にも、find_by_tag()、find_by_name()、find_by_text()などのメソッドがあります。
# I recommend using single quotes
search_bar_xpath = '//*[@id="lst-ib"]'
# index 0 to select from the list
search_bar = browser.find_by_xpath(search_bar_xpath)[0]
上記のコードは、この個々のHTML要素のナビゲーションを提供します。クローリングには、2つの有用なメソッドがあります。それは、fill()とclick()です。
search_bar.fill("CodingStartups.com")
# Now let's set up code to click the search button! search_button_xpath = '//*[@id="tsf"]/div[2]/div[3]/center/input[1]' search_button = browser.find_by_xpath(search_button_xpath)[0] search_button.click()
上記のコードはCodingStartups.comを検索バーに入力し、検索ボタンをクリックします。最後の行を実行すると、検索結果ページに移動します!
ヒント:ログインページをナビゲートするには、fill()とclick()を使用してください。
ステップ4:スクレイピング!
この演習の目的を達成するために、最初のページの各検索結果のタイトルとリンクをスクレイピングしていきましょう。
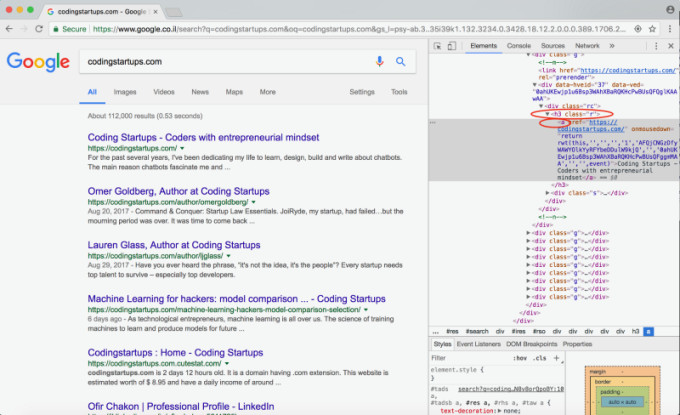
各検索結果は、クラス「r」のh3タグ内に格納されていることがわかりますね。また、スクレイピングしたいタイトルとリンクの両方がaタグに格納されていることにも注意してください。
ハイライト表示されたタグのXPathは次のとおりです。
//*[@id=”rso”]/div/div/div[1]/div/div/h3/a
しかしこれはまだ最初のリンクです。私たちが欲しいのは最初のリンクだけでなく、検索ページのすべてのリンクです。そのため、find_by_xpathメソッドがすべての検索結果をリストに返すように、これを少し変更しましょう。これがその方法です。以下のコードを参照してください:
search_results_xpath = '//h3[@class="r"]/a' # simple, right?
search_results = browser.find_by_xpath(search_results_xpath)
このXPathは、クラス「r」を持つすべてのh3タグを検索するようにPythonに指示します。次に、h3タグの内部で、aタグとすべてのデータを抽出します。
さぁ、find_by_xpathメソッドが返した検索結果のリンク要素を使って、これを繰り返してみましょう。各検索結果のタイトルとリンクを抽出します。それは非常に簡単な作業です。
scraped_data = []
for search_result in search_results:
title = search_result.text.encode('utf8') # trust me
link = search_result["href"]
scraped_data.append((title, link)) # put in tuples
このデータをクリーニングするのは、時にはイライラする作業です。ウェブ上のテキストは非常に乱雑です。以下は、データのクリーニングに役立つ方法です。search_result.text
.replace()
.encode()
.strip()
これですべてのタイトルとリンクがscraped_dataリストに追加されました。データをcsvにエクスポートしましょう。CSVライブラリはごちゃごちゃしているので、私はPandasのデータフレームを使います。それはたった2行です。
df = pd.DataFrame(data=scraped_data, columns=["Title", "Link"])
df.to_csv("links.csv")
上記のコードは、ヘッダーのタイトル、リンク、そしてscraped_dataリストにあったすべてのデータを含むcsvファイルを作成します。おめでとうございます!これでデータを取得する(取り戻す)ことができましたね!
全体像をつかみたい場合は、全体のコードをこちらから参照してください。あなたのGitHubアカウントで利用できます。
ウェブスクレイピングは、必須のウェブ開発スキルです。ウェブ開発で成功を収めたいですか?ウェブ開発のワークフローに最適なツールについては、このブログ記事を参照してください。
最後までお読みいただきありがとうございます!Lauren Glassと申します。私はテルアビブ在住の起業家であり、データサイエンティストであり、開発者です。
CodingStartups(ブログの名前)で私の元の投稿文と他の記事をチェックしてみてください。
インスタグラム@ljglassのフォローをお願いします。
CREDIT:原著者の許諾のもと翻訳・掲載しています。
[原文]Mastering Python Web Scraping: Get Your Data Back (Posted Sep 12, 2017) by Lauren Glass